InChI Syntax
InChI is an IUPAC standard and software package for chemical identification. For most small organic molecules likely to be found in a drug discovery program, a stockroom, or a chemical database, the InChI software creates a unique character sequence. InChI is useful because it enables fast exact-structure lookup within a single database and among different databases.
But moving past the practical win InChI offers, we're faced with a question that at first glance may seem rather esoteric. What rules, if any, can every InChI identifier be expected to follow? It turns out that this question and its answers have some important practical consequences for many InChI users.
Does InChI Have Syntax?
Recently, I ran a Twitter poll about InChI as a standard. The idea was to explore which of two possible sources should be considered "authoritative" on the topic of what InChI is: the source code distribution or the Technical Manual.
Can IUPAC InChI software ever generate a syntactically invalid InChI? How far does "the code is the standard" go?
— Rich Apodaca (@rapodaca) April 12, 2021
Imagine that your copy of the InChI software gives a string whose syntax differs from what's in the Manual. Where is the error?
The third option, "There is no InChI syntax," was added as an afterthought. I expected it to get no votes. Then it tied for first (with "See results"). Maybe my earlier article, Parsing InChI: It's Complicated, had something to do with this. There, I noted that it's not generally possible to transform an InChI into the molecular graph that created it.
Either way, is it possible that InChI has no syntax?
Identifiers and Syntax
InChI can be regarded as a black-box identifier, devoid of any meaningful internal structure. From this perspective, it's possible to think that InChI itself has no syntax, or that any syntax that may exist is irrelevant.
The problem is that all identifiers by their very nature have internal structure, even if that structure is primitive. Without internal structure, there would be no way to even recognize an identifier as such. Worse, there would be no practical way for users to avail themselves of the services being offered by the identifier.
Many examples from everyday life support this view. Consider national identification numbers such as a Social Security number (SSN). A claim that a social security number contained the letter "P" would rightly be viewed as suspect. As the IRS itself notes, "Your nine-digit Social Security number is your first and continuous connection with Social Security." A valid SSN therefore consists of exactly nine digits. SSN is a dumb identifier in that there isn't much internal structure, but the structure is undeniable.

Chemical Abstracts Service Registry Numbers (CAS numbers) offer a more chemistry-specific example of a dumb identifier with syntax. As noted by CAS itself:
A CAS Registry Number® includes up to 10 digits which are separated into 3 groups by hyphens. The first part of the number, starting from the left, has 2 to 7 digits; the second part has 2 digits. The final part consists of a single check digit.
Every identifier, regardless of what it identifies or how, has an internal structure of some kind. The name for this characteristic is, of course, syntax. The most relevant definition of the word by Merriam-Webster says that syntax is:
a connected or orderly system : harmonious arrangement of parts or element
Given that InChI is a chemical identifier, what can be said about its harmonious arrangement of parts or elements?
Why Syntax Matters
Before discussing what some authoritative sources have to say about InChI syntax, it's important to understand why InChI's syntax matters in a practical sense. I've identified four reasons:
- Extracting information. As we'll see, InChI exhibits the characteristics of both an identifier and a representation. Information about the molecule being identified might be available, with some caveats, by treating InChI as a kind of molecular representation. For example, InChIKey works on this principle. As we'll see, InChI was even designed specifically with this use case in mind.
- Understanding InChI's scope and limitations. Knowing whether InChI's internal structure supports a given application should be a central part of any evaluation effort.
- Extending InChI. When InChI lacks the internal structure for a given application, it might be possible to fill the gap with an extension. However, that extension must not conflict with existing syntax.
- Validating InChI. If an InChI identifier broke one or more syntax rules, should it be considered valid? Even more importantly, how would you know that a rule had been broken? These questions can only be answered with a detailed, systematic description of InChI's syntax.
InChI Syntax
The most detailed and authoritative source of information on InChI's syntax can be found in the Technical Manual published by InChI Trust. The Manual describes a chemical line notation whose organizing principle is layers.
An InChI layer is a sequence of characters that encodes a particular aspect of molecular structure. Each layer is separated from its successor by a forward-slash symbol (/). The following figure from the Technical Manual gives an overview.
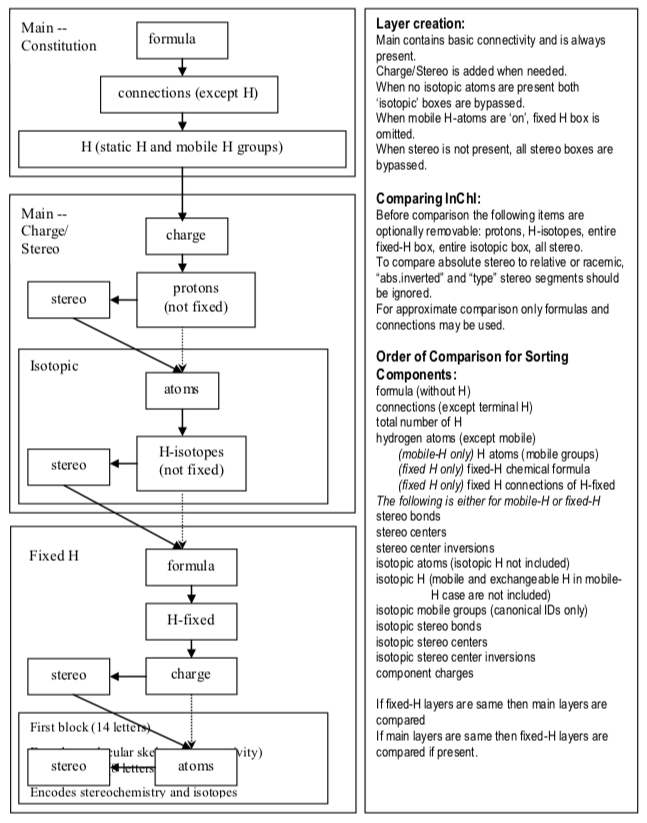
An entire section (III. Discussion) is mainly dedicated to elaborating the concept of InChI layers:
- IIIb. Construction of the InChI. Ordering and assembly of layers.
- IIIc. InChI Components. Special handling for disconnected molecular graphs.
- IIId. The Five InChI 'Layer' Types. Details for the available layer types: Chemical Formula; Connections; Charge; Stereochemical; Isotopic; and Fixed-Hydrogen.
- IIIe. InChI Structure. Enumerates all possible layers and explains their relationship to each other.
- IIIf. Standard and Non-Standard Identifiers. Using the prefix to indicate whether or not certain software settings have been applied.
Additionally, three Appendixes refine InChI layers further:
- Appendix 2. Abbreviations and Layer Precedence. Encoding InChI layers and relating them to each other.
- Appendix 3. Extracting Layers from InChI. How to disassemble an InChI into meaningful segments.
- Appendix 4. Comparing InChI Representations for Finding Identical Compounds. Attenuating the precision of an InChI though selective deletion of layers.
Layers are clearly the central abstraction in InChI. The InChI team re-enforced this idea in its article InChI, the IUPAC International Chemical Identifier, noting: "The most important aspect of InChI is its hierarchical, layered nature."
To summarize, a rich syntax courses through the veins of each InChI identifier. From its inception, InChI identifiers were designed to be split up and repurposed as explained by the authoritative documentation.
Clearly an InChI syntax exists. But this just brings us back to the question I posed in my Twitter poll: where does the specification of the InChI syntax reside — in the source code of the InChI distribution or in the Technical manual? Which one is "the standard?"
That's really a question for the InChI team to answer. For now it's clear that rules of InChI syntax not only exist, but were deliberately designed from the outset. A more immediate question is: what are the syntax rules for InChI and how should that information be conveyed?
Informal Syntax Descriptions
For as long as people have been analyzing languages, they've tried to come up with ways to describe syntax. The InChI Technical Manual offers some examples of why spoken language descriptions (and graphics) often fall short when used to describe syntax:
- It's hard to write spoken languages both concisely and precisely.
- words often have ambiguous meanings.
- It's hard to keep all the context needed to parse a spoken language standard in your head at the same time.
- There's no automated way to transform a spoken language technical description into running code.
Fortunately, there is an answer to all of these problems when it comes to describing syntax: a formal grammar. A formal grammar, being a very limited form of expression, can be both concise and precise in describing syntax. As a result, ambiguities and contradictions are easy to spot. Because they're compact, formal grammars can be much easier to understand than freeform text and graphics. Finally, formal grammars can be machine-translated into running code that can parse and validate examples of the underlying language.
This blog has covered formal grammars from several angles. Here are some articles that show how to apply formal grammars to the SMILES language:
- SMILES Formal Grammar
- SMILES Formal Grammar Revisited
- Abstract Syntax Trees for SMILES
- Let's Build a SMILES Parser in Rust
Conclusion
InChI is both a chemical identifier and a chemical representation system. This dual nature can be both confusing and empowering. As an identifier, InChI enables fast exact structure lookup. As a representation, InChIs offers much more. The key to using InChI as a representation lies in understanding its syntax. What's lacking is a concise yet precise description of it. A future article will address this point.