The SDfile Format
Chemical datasets often need to be exchanged with high fidelity. A number of file formats enabling such exchange can be found in the wild but the most common by far is the structure-data file (SDfile, aka "SD File," "SD file," or "SDF"). Although the format appears simple on the surface, there are some subtleties to consider. This article takes a closer look at the de facto standard for information exchange in cheminformatics.
Source Documentation
The SDfile format was originally developed by Molecular Design Limited (MDL). Through several acquisitions spanning decades, MDL's intellectual property was eventually acquired by BIOVIA, a subsidiary of Dassault Systemes. This history means that it's still possible to find references to MDL in connection with SDfiles. For example, the MIME type for SDFile is chemical/x-mdl-sdfile.
For many years MDL and its successors have published a technical specification for SDfile and its larger family of file formats. The name of this document has changed somewhat over time, but always includes the text "CTfile Formats." The most recent incarnation, freely downloadable from BIOVIA's website, is called CTfile Formats BIOVIA DATABASES 2016. The discussion that follows is based on this document unless otherwise noted.
Overview
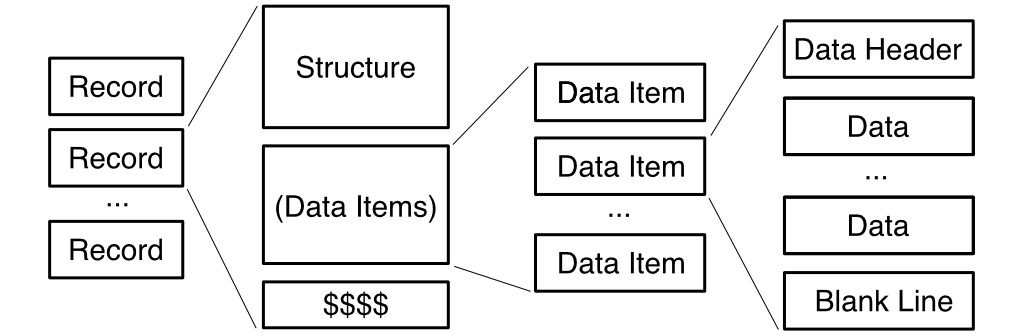
SDfile is a member of a family collectively known as "CTfile formats." The initials "CT" stand for connection table, which can also be referred to as a "Ctab". A Ctab is a form of molecular representation based on the edge list graph representation. The molecular graph encoded by a Ctab is composed of a header, a block of atom properties, and a block of edge properties. One or more Ctabs can be found within every member of the CTfile family.
An SDfile is a list of records typically composed of one Structure and a list of zero or more Data Items. A Structure is encoded in either of the two Ctab Molfile formats, V2000 or V3000. Future articles will explore Molfiles in depth. Each Data Item is itself composed of a Data Header, zero or more Data lines, and a blank terminating line, in that order.
Lines All the Way Down
Like its CTfile relatives, SDfile is a line-oriented format. Among other consequences, this means that in diagrams like the one in the previous section, line breaks produce the boundaries between elements. Likewise, each element is composed of one or more lines concatenated together.
For example, a Data Item consists of a minimum of three lines: a one line Data header; one Data line (which may be blank); and a blank line. Concatenating these lines together produces a Data Item. Splitting the lines allows them to be processed individually.
Given this focus on lines as a compositional unit, it's surprising to see nothing in the specification about what constitutes a valid line break. Given that SDfiles can be generated from a wide variety of software systems and on a diverse array of computing platforms, all possibilities should be expected: carriage return (\r, old-style Mac); linefeed (\n, macOS/Unix); and carriage return-linefeed (\r\n, Windows). Multiple line break styles in the same file would appear to be consistent with the specification.
Also surprising is the lack of guidance with respect to maximum line length. The only hint of a limit occurs with the length of a Data line, which may be up to 200 characters in length. This restriction presumably excludes the line break. Previous versions of the technical documentation placed an 80-character limit on lines within a V2000 molfile. The more recent BIOVIA documentation has eliminated this cap.
Structure
The structure component of an SDfile is represented as either a V2000 or V3000 Molfile. The specification does not preclude the appearance of both formats in the same SDfile. Both formats require the same terminator (M END) as the last line. This makes it simple to demarcate the structure component of each record.
Is the structure component optional? Yes, but only within a datfile. A datfile is an SDfile without a structure component or $$$$ delimiters. In other words, a datfile holds a single record without a structure. Given widespread support for key/value data formats such as XML and JSON, datfile seems to have rather narrow utility today.
Data Header
Aside from the V2000/V3000 Structure component, the Data Header is the most complex element of an SDfile. This part of the SDfile spec has clearly evolved over the years. Legacy vestiges of long-gone applications make this part of the specification particularly difficult to support as written.
A data header line starts with the greater than character (>). Additionally, the Data Header line must contain at least one of the following two possible elements:
- a field name enclosed in angle brackets; or
- a field number
A field name starts with an alphabetic character ([A-Za-z]) and is followed by zero or more alphanumeric characters or an underscore (_). The spec mentions no upper bound on field name length. Specifically excluded as valid characters in a field name are the characters: hyphen (-); period(.); less than (<), greater than (>); equals (=); percent (%); and space ( ).
Field name is a rich source of errors when reading and writing SDfiles. A common departure is the presence of a space character ( ), which is specifically disallowed (see, for example, ChEBI). Given that both angle bracket characters (< and >) are invalid within a field name, a pragmatic approach is to accept any field name appearing within angle brackets.
A field number consists of the characters DT immediately followed by one or more digits ([0-9]). As with field name, there is no upper bound on the length of field number.
Additionally, a data header may have any number of extra characters interspersed at any point after the staring character (>). This "optional information" may or may not be interpreted by an application. However, the presence of valid optional information should not raise errors.
One form of structured optional information is supported: external registry number. To signal its presence, an external registry number is wrapped in parentheses (( and )). It's not clear whether multiple external registry numbers are valid, or whether they can be nested. Regardless, the utility of a registry number encoded within optional information is debatable given that both V2000 and V3000 Molfiles support an external registry number field.
Aside from a greater than symbol (>) or a line break, all characters are allowed on a data header line.
By way of summary, examples of valid Data Headers include:
> <Melting_Point>><IC_50>(JNJ-5207852)> DT13>Arbitrary Data Goes Here<pKi_HISTAMINE_H3>
Data Value
The documentation is unfortunately less than clear about the composition of data values. As noted previously, a data value immediately follows the data header line, and is composed of zero or more lines terminated by a blank line.
Ideally, a data item without a value would simply be omitted. However, if it is included, the correct format for a valueless data item is a data header followed by exactly one blank line:
> <WITHOUT_VALUE>
> <WITH_VALUE>
datadatadata
$$$$
Grid Not Guaranteed
Shape plays a crucial role in how data sets are consumed and created. For example, CSV and Excel files are grids. Every record (row) contains the same fields, listed in the same order, as any other other record. Although fields may be blank or undefined, they are guaranteed to exist. Grid formats often supply the names of fields in a header row, but this isn't always the case.
An SDfile, in contrast, is not necessarily a grid. A given record may have more, fewer, or the same number of Data Items as another record. Each record defines its own list of fields and their order. Although it's possible for every record in an SDfile to have the same number of fields with the same Field Names, listed in the same order, nothing in the specification guarantees this constraint.
Depending on the application, the non-grid shape of SDfile data can become important. One approach is to treat SDfiles as grids in which each row can optionally elide undefined or blank fields. However, this treatment makes assumptions about the data that may not be true.
Character Encoding
No character encoding for SDfiles is specified in the BIOVIA spec. In practice, UTF-8 appears the offer a broadly-useful default.
Alternatives
Useful though it may be, SDfile won't be the best tool for every job. Here's a short list of alternatives worth considering:
- SMILES file. A SMILES file is a text-based format in which each line contains an optional SMILES representation and associated data fields. A header line may used, but it must begin with a whitespace character and its presence would be outside the specification. Like SDfile, there is no grid guarantee. SMILES offers the main advantage of compactness due to the reduced space requirements compared to Molfile. If atomic coordinates are not required, SMILES files make a good alternative to SDfiles.
- CSV. CSV files are ubiquitous, as are readers and writers for the format. As such, SDfiles lend themselves well to reformulation as CSV files to take advantage of standard tooling. If Molfiles are required, they can be included by wrapping them within quotation marks to avoid triggering a new record.
- JSON. Like CSV, JSON enjoys broad tooling support. Unlike XML, JSON imposes minimal restrictions around format and overhead. An SDfile is at its core a key-value store, so recasting as JSON should not pose big challenges. Ready access to generic tooling would be an important advantage of this approach.
Conclusion
Any application dealing with chemical structure metadata will likely need to support SDfile input, output, or both. A specification has been published and can be readily obtained, but gaps are not difficult to find. This article attempts to point out and where possible fill some of the larger gaps as an aid to those using SDfiles at a low level.