Virtual Hydrogens
What's the difference between computational chemistry and cheminformatics? Computational chemists encode all the hydrogens. This tongue-in-cheek statement, whose origins I don't recall, isn't far off the mark. It stands to reason that if hydrogens are going to be deleted, there needs to be a good way to bring them back. This article proposes some language intended to simplify what has become an unnecessarily complex problem.
Hydrogen Suppression
The practice of ignoring hydrogens to emphasize the carbon framework has a long tradition in organic chemistry. As far back as 1872, Kekulé himself used the convention when discussing alternative structures of benzene:
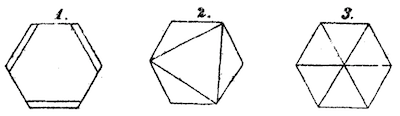
Over the next 100 years or so, authors experimented with hydrogen suppression on and off. By the 1970s, most chemists had standardized on the hydrogen-suppressed form now in common use. In particular, hydrogens are only added when the count is ambiguous or in certain special cases such as carbonyl carbons.
As the field of cheminformatics gathered steam the 1960s, it naturally gravitated toward hydrogen-suppressed representations. Given the severe resource constraints at the time, however, the earliest systems were based not on individual atoms, but on collections of them. The best-known example from this period is Wiswesser Line Notation (WLN)), which is based on functional groups.
Eventually it became feasible to represent each atom individually. But rather than elevating hydrogens to first-class status, the new systems being developed after the 1970s left hydrogens in the economy section, just like the structure drawings being published by organic chemists.
Somewhere along the line, the term "implicit hydrogen" was adopted. The Merriam-Webster dictionary defines "implicit" as: "capable of being understood from something else though unexpressed."
Unfortunately, the terms "implicit hydrogen" and "hydrogen suppression" have come to mean the same thing. They aren't. The resulting confusion has, I suspect, led to many mis-characterized chemical structures over the years.
Implicit Hydrogens
An implicit hydrogen, as the name suggests, is a hydrogen atom whose presence can only be deduced by "something else." That "something else" is a set of conventions referred to valence rules or a valence model.
A valence model associates certain elements with one or more ideal hydrogen counts. For example, carbon has an ideal hydrogen count of four. Nitrogen has an ideal hydrogen count of three. Oxygen has an ideal hydrogen count of two, and so on. Valence models usually apply to a subset of the periodic table.
The implicit hydrogen count of any atom subject to a valence model can be determined by a simple procedure. First, determine the number of electrons donated by the atom to bonding. This value equals the sum of formal bond orders and is sometimes called "valence." Next, subtract the bonding electron count from the atom's ideal hydrogen count. The result is the atom's implicit hydrogen count. The implicit hydrogen count for an element not covered by a valence model is undefined.
Consider ethane with all hydrogens suppressed. We want to determine the implicit hydrogen count of a carbon atom. We note one single bond to a neighboring carbon, so the bonding electron count is one. Our valence model assigns carbon an ideal hydrogen count of four. Subtracting one for the bond to the neighboring carbon yields three hydrogens. This is the implicit hydrogen count for a carbon atom in ethane. The same procedure would yield two as the implicit hydrogen count for a carbon in ethene, and one for a carbon in ethyne.
To recap, an implicit hydrogen is one whose presence can only be deduced from a valence model. The implicit hydrogen count of an atom not covered by a valence model is undefined.
Explicit Implicit Hydrogens
Clearly, there's more to hydrogen suppression than just implicit hydrogens and valence models. For example, organic chemists follow a modern drawing convention in which hydrogens attached to carbon are implicit, but the hydrogens attached to heteroatoms are explicit. The same phenomenon can be found in cheminformatics toolkits and exchange formats such as SMILES. Recall that the implicit hydrogen count of an atom not covered by a valence model is undefined. Or, consider a system in which valence models have been abolished altogether. In either case, brevity draws us toward hydrogen suppression, but no valence model applies.
Given the lack of an alternative, the phrase "explicit implicit hydrogen" has taken root to describe the atomic attribute representing a hydrogen count. The most obvious problem is that the terms "explicit" and "implicit" conflict. It's a linguistic pretzel. But the deeper problem is that the term "implicit hydrogen" carries the very specific association with a valence model. This seepage causes considerable problems to those implementing or using cheminformatics systems.
Virtual Hydrogen
Can we do better? I think so. I'd like to propose the term virtual hydrogen.
A virtual hydrogen is a hydrogen atom encoded, not as a node and edge combination in a molecular graph, but within an atomic integer attribute. To convert an atomic hydrogen, delete it and its bond, and increment the virtual hydrogen count by one. To convert a virtual hydrogen, decrement the count and add an atomic hydrogen with bond. Multivalent hydrogens, as found in boranes for example, are not eligible for such conversion. Virtual and atomic hydrogen representations and both be present at the same atom.
Merriam-Webster defines "virtual" as: "being such in essence or effect through not formally recognized or admitted." The word "virtual" is also used extensively in computer science as reflected by such terms as: "virtual keyboard;" "virtual reality;" and "virtual memory." In these contexts, the word assumes a meaning similar to the Macmillan Dictionary definition: "almost the same as the thing that is mentioned." A virtual hydrogen is almost the same as an atomic hydrogen.
There's no linguistic or logical barrier to encoding "virtual hydrogens" explicitly. On the contrary, virtual hydrogens must be explicitly encoded.
The concept of virtual hydrogens allows us to talk about hydrogen suppression more precisely. For example, the mandatory hydrogen at pyrrole nitrogen (e.e., [nH]1cccc1) is virtual. Those hydrogens deduced to be present in propane (CCC) are implicit. Encoding a hydrogen as a standalone atom, as in [CH3][H] makes it atomic (note the corresponding deduction from the hosting carbon virtual hydrogen count). The V2000 Molfile format supports virtual hydrogens, but in a roundabout way. InChI eschews implicit hydrogens altogether in favor of virtual hydrogens encoded within a dedicated layer.
Conclusion
Organic chemists discovered long ago that drawing every hydrogen atom leads to noise. Hydrogens can be safely suppressed, but only when the rules for interconversion are both simple and explicit. Two distinct forms of hydrogen suppression are possible, but poor terminology has led to their conflation. Implicit hydrogens are encoded through the use of a valence model. A second form of hydrogen suppression replaces atomic hydrogens and their bonds with a hydrogen count attribute. This latter form of hydrogen suppression requires an unambiguous name, and "explicit implicit hydrogens" just won't cut it. "Virtual hydrogen" avoids linguistic convolution while at the same time cleanly severing the link to a valence model.